
The Internet seems awash with ‘click-bait’ and sponsored content – articles created primarily to generate money, sometimes plagiarised, misleading, exaggerated, or provocative just to get views. The good stuff – articles often written simply because it’s good to share knowledge and ideas – is getting harder to find.
My proposal is to create a search engine that, rather than systematically crawl the web, starts with a seed corpus of high quality links, and fans out from there, stopping when the quality drops. The result will hopefully be a searchable index of pages that were created to impart information rather than to earn cash from eyeballs.
As a proxy for quality, I’ll use the number of ‘hits’ emitted by uBlock Origin (uBO) as a page loads. That is, if one page results in 50 blocked requests, then I’d suspect this content is heavily driven by commercial interests, and therefore has a lower likelihood of being original or worthwhile content. If it has 5 blocked requests, there’s a higher likelihood that it’s original and interesting.
Help by submitting your interesting finds using this Firefox Add-on
GNU GPLv2 Licensed. Source-code available here
There are many things wrong with such a simple assumption, but I think it’s a promising starting point because, of the first 300k links extracted from a known high quality source (Hacker News, as described below), some 85% of the pages linked to resulted in 9 or fewer uBO hits, while 66% of the pages resulted in 3 hits or fewer. For 31% of these links, uBO didn’t block any requests at all.
As an experiment to determine how feasible this is, I am extracting links from a source with generally high quality content, initially Hacker News (HN) stories and comments, and for each link record URL along with the HN-score. The result is a list of URLs that I then score via uBO, storing the extracted plain text, along with the number of uBO hits, in a MongoDB collection for subsequent indexing.
The main goals are a) to be easily reproducible by others, b) to be resource efficient for cheap VPS deployment, and c) to be scalable as new sources are included. So, I want a low barrier for anyone who wants to join the indexing effort, and the means to grow if more people join.
With a seed of 5M URLs, and a further two levels of, say, 5 links per URL, the index would cover 125M pages, which would be around twice the level of search engines circa 1998. I reckon that could be achieved with 20 low-end VPS instances over a period of 4 months.
Getting the Seed URLs
I use JavaScript on Node to extract story URLs, and any hrefs embedded in comments, from the Hacker News API that’s available on Firebase. The story titles and points, and perhaps even karma of comment authors might also be used as meta-data to score and index the URLs. From a sample of 50K of the most recent HN items, I extracted 15K URLs, but further testing suggest around 25K URLs per 100K HN items.
If this ratio holds, then I’d expect around 5M URLs to process, given that we’re fast heading towards 20M HN items.
Analysing Content of the URLs
I use Puppeteer to access each URLs in the list, and record, for each, the number of requests blocked by uBlock Origin. This is a relatively slow process, since the browser has to fetch the page and process its associated resources, in order to allow uBlock Origin to identify requests that should be blocked.
However, multiple pages can be created in parallel (effectively multiple tabs in Puppeteer), and the system seems capable of handling 20 or more pages at once in the Puppeteer instance. However, this is entirely dependent on the demands of the pages being loaded, and with the 4GB RAM and 2 CPUs on the VPS I’m currently running, the load average hovers between 7 and 10, with close to 100% CPU utilisation for a current average of 1.7 pages per second.
When the page is loaded (when the ‘load’ event has triggered, followed by a predefined delay), I take the original DOM content, and process it through a text extractor (jusText, though I am also considering Dragnet). I intended processing the results through RAKE or Maui to identify keywords and phrases, mainly to cut down on space required and words to index, but decided against this and store the extracted text entirely – highlighting of search results needs this.
The metadata I keep include the HN score associated with the item (comment or story), the length of the extracted text, and of course the number of requests that uBlock rejected. Karma and user id might also be useful but, particularly with the latter, it feels slightly intrusive to appropriate personal data in this way. The jury’s still out on that.
If I can average one URL processed per second, then the corpus would be processed in around 52 days. Currently, processing is running at 1.7 URLs per second, so if that rate holds, then the seed can be analysed in 30 days. The average size of data held for each URL seems to be just over 6KB (e.g. the URL itself, meta-data, and the extracted body text), so the total source for indexing should require around 30GB of storage, which should fit in the 40GB disk on my current VPS.
The data is, for now at least, stored in a MongoDB server, which forms the source data for the searchable index. Though MongoDB has some great built-in text-search facilities, it breaks due to lack of memory on a low-end VPS (around 1GB free on a 2GB instance), even with a relatively small number of documents. Maybe it could be coerced into working, but I decided going straight to Lucene would be the best way forward.
Build a Search Engine
The search engine itself has been built on Lucence, with a very simple HTML front-end built using Java Servlets, since a JVM would already be running Lucene. It accepts a query string and, optionally, thresholds for uBlock hits and HN scores of the stories or comments that the page’s link came from, and returns the top 100 hits.
Even with mostly default behaviour, Lucene is generating indexes at roughly 30% of the input size, at 15 minutes per 0.5M pages over the network, and is already providing fast searches with queries that support boolean operators (remember + and – to include and exclude words?) and highlighting of results. A truly awesome piece of software, and I feel I’ve barely scratched the surface.
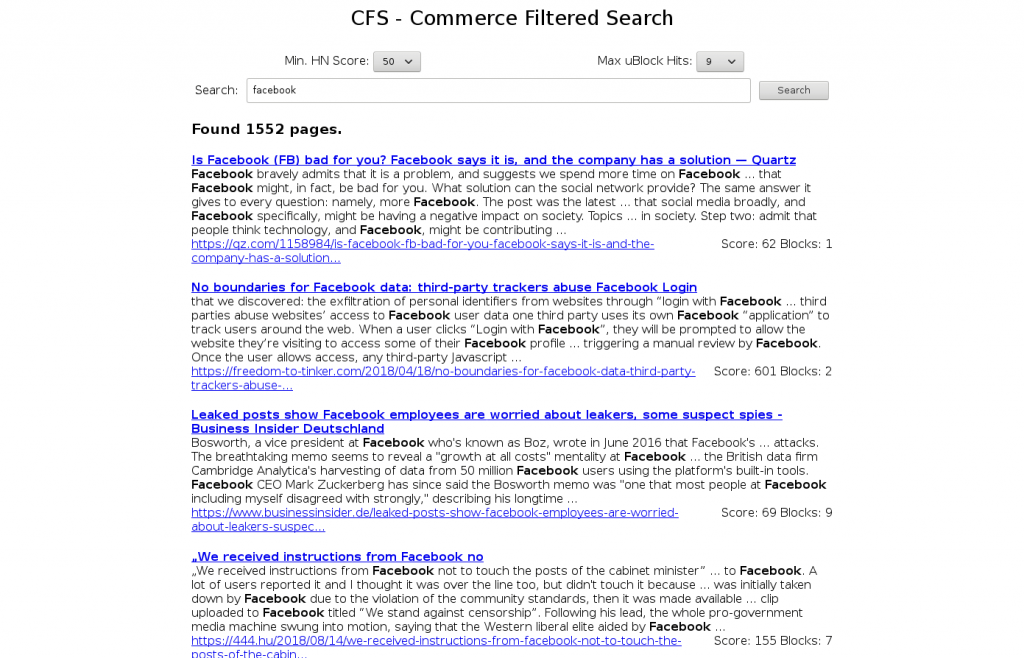
The index currently has around 750,000 pages, but even so it’s interesting to search on. I get a sense of ‘discovery’ from it, something I feel is missing from the big search engines which, while great at answering very specific questions or finding stuff to buy, seem worse at finding the little gems that made the Internet interesting. However, the URLs were harvested from Hacker News, so I really shouldn’t be too surprised that I find the results interesting.
One of my next tasks is figuring out how best to search a distributed index, or else to merge multiple indexes together. Maybe ElasticSearch or Solr will be a tool for this.
Do you want to help?
When I have a repeatable process, then I’ll push the code so far to GitHub along with instructions on how to build the environment. For this project, I’m running Debian 9.3 on a 2GB and a 4GB 2-CPU VPS server with combined 60GB storage. If this sounds interesting, and you want to contribute (and want to release your contribution under a free-software license), then please get in touch via the comments or directly at kevin@susa.net.